 DonutBlog
DonutBlogAnalyse de mon tout premier protocole de communication
J’analyse ici le tout premier protocole de communication que j’ai appris à utiliser : ma voix.
Cette étude commence par une analyse des caractéristiques physiques (support de transmission, bande passante, vitesse, portée). Nous étudierons ensuite les caractéristiques de niveau supérieur (protocole, compression, chiffrement etc.). Dans la mesure du possible, j’essaierai de replacer les performances de ce protocole dans le contexte des protocoles informatiques utilisés depuis une cinquantaine d’années.
Couche physique
La voix est un protocole de communication basé sur la propagation des ondes acoustiques. Il est donc nécessaire d’avoir un milieu conducteur entre les différents interlocuteurs. Ce milieu est optimalement de l’air. Techniquement n’importe quel milieu gazeux pourrait faire l’affaire pour peu que les conditions de pression et de température soient nominales, mais je n’ai personnellement pas eu l’occasion de les tester. La vitesse de propagation est naturellement celle du son (environ 340 m/s) et la portée est de l’ordre de la dizaine de mètre. J’ai la possibilité d’amplifier le signal d’émission pour compenser la distance et/ou le bruit ambiant : on dit alors que “je gueule”. J’avoue ne pas avoir eu l’occasion de tester la distance maximale que je peux atteindre de cette façon.
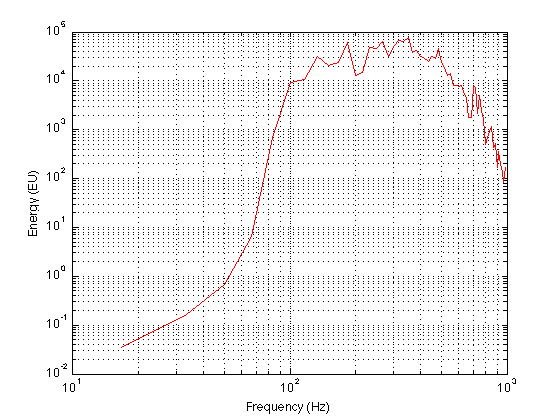
Le domaine fréquentiel de ma voix couvre une bande allant de 100 Hz jusqu’à 1000 Hz environ, ainsi que l’illustre la figure ci-dessous. Cette courbe a été obtenue par l’enregistrement d’une trentaine de secondes de données (lecture d’un article de journal).
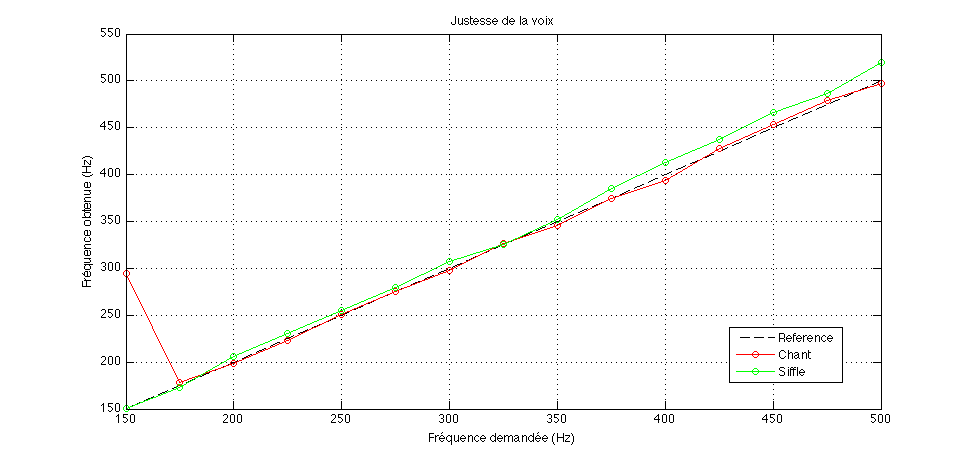
La justesse de ma voix est une question critique : est-ce que je chante juste ? J’ai développé dans cet objectif un petit programme qui me demande de reproduire, soit par chant soit par sifflement, une note imposée. Le programme enregistre ma tentative et la compare à la fréquence de référence. J’estime de cette façon que ma justesse est de l’ordre de quelques Hertz (voir figure ci-dessous). J’ignore à partir de quand on estime chanter faux. Notons que le protocole de mesure peut être amélioré : à 150 Hz, il semblerait que je chante faux alors qu’en fait, je chantais juste à l’octave supérieure ! Par ailleurs, à l’heure de transcrire cet ancien article, je réalise que j’aurais du tracer ces courbes en relatif et non pas en absolu !
Couche communication
La voix est un protocole que j’utilise généralement en mode connecté et avec acquittement : j’interagis dynamiquement avec la personne avec qui je parle et j’attends sa réponse avant de continuer ma communication. Voici, à titre d’exemple, une communication que j’aurais pu avoir :
Pierre - Bonjour !
Interlocuteur - Bonjour !
Pierre - Ca va ?
Interlocuteur - Très bien et toi ?
Pierre - Ca va bien, je te remercie. Je suis actuellement en train d’écrire un article sur ma voix
Interlocuteur - Oh c’est très intéressant ça, tu me le feras lire ?
Pierre - Ca risque d’être difficile car tu es un personnage sans nom que je viens juste de créer pour illustrer mon propos…
Je pense être compatible avec les normes sociales actuellement en vigueur. Je suis en effet capable d’employer le vouvoiement ainsi que la majorité des formules de politesse.
Je supporte quelques protocoles linguistiques avec plus ou moins de bonheur (français, anglais et italien).
L’état de phase de ma voix (la brique insécable de données) est la syllabe dont la durée caractéristique est de l’ordre de $10^{-1}$ s. Chaque syllabe a une valence de 2 ou 3 : c’est le nombre de lettres nécessaires pour la décrire (“BA” à une valence de 2, “CHA” à une valence de 3).
J’ai mesuré mon débit en listant un article de journal quelconque. Il est d’envrion 15 octets/s en lisant normalement et je peux monter à 24 octets/s en lisant de façon monocorde. Je pense que les commentateurs sportifs sont capables de faire mieux.
On peut comparer ces débits avec les standards proposés par l’Union Internationale des Télécommunications (agence des Nations Unies) sur leur site internet.
| Norme | Année | Débit (octets/s) |
|---|---|---|
| V.23 | 1988 | 150 |
| V.32 | 1993 | 1200 |
| V.34 | 1998 | 3700 |
| V.92 | 2000 | 7200 |
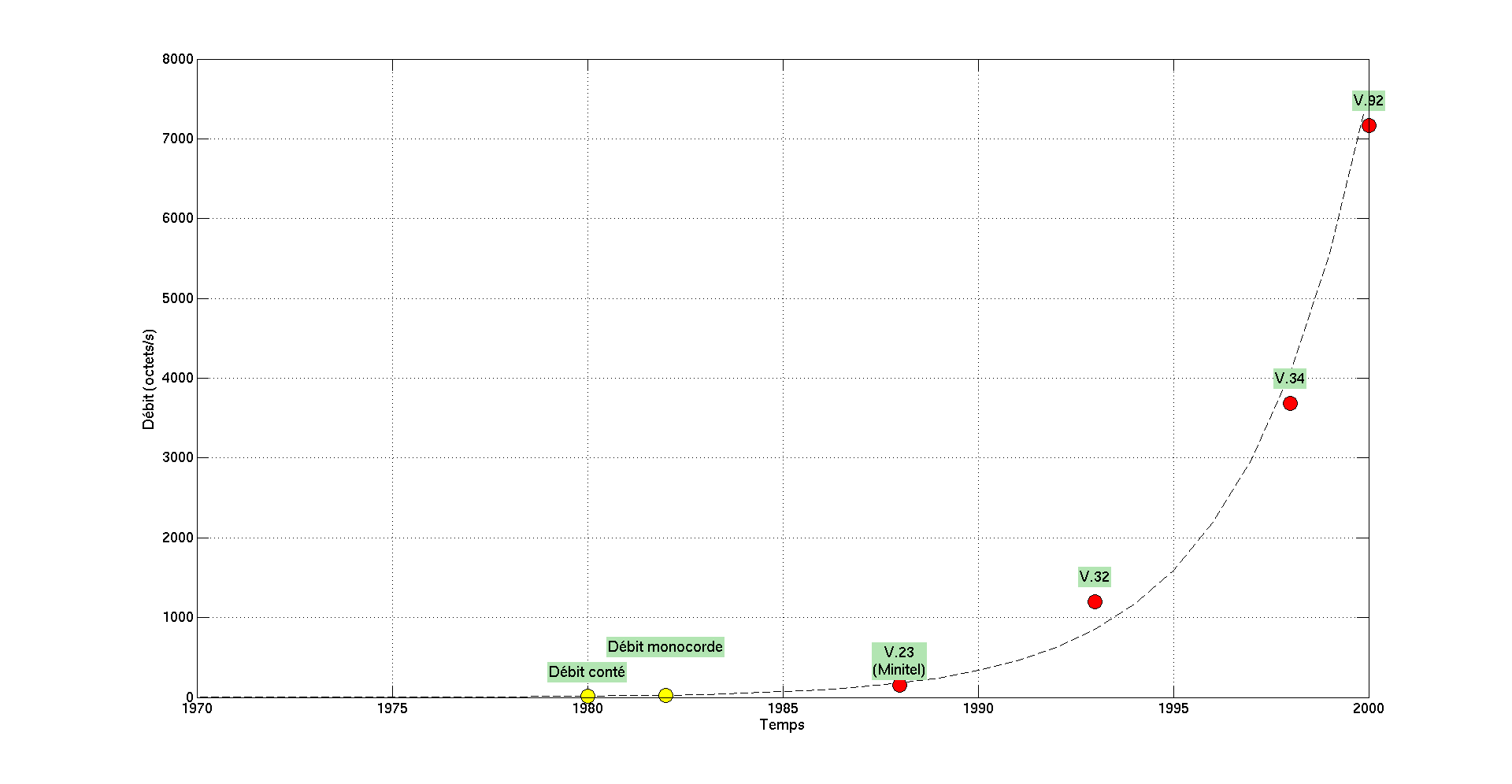
En supposant une évolution exponentielle de la vitesse de communication, nous pouvons en déduire l’année où mes deux protocoles “débit conté” et “débit monocorde” auraient pu être technologiquement inventés. Je trouve ainsi 1980 pour le débit conté et 1982 pour le débit monocorde. Etant né en 1983, je trouve ces résultats plutôt remarquables. Dans la figure ci-dessous, les points en rouge correspondent aux 4 standards de l’ITU sélectionnés. Les points en jaune correspondent à mes deux débits de voix expérimentalement mesurés.
| Protocole | Année | Débit (octets/s) |
|---|---|---|
| Débit conté | 1980 | 15 |
| Débit monocorde | 1982 | 24 |
J’utilise par ailleurs très peu la redondance syntaxique en ce sens où j’ai à cœur de prononcer chaque lettre que j’émets. Tout au plus peut-on comptabiliser quelques sporadiques lettres doubles ou muettes. En revanche, j’ai comme tout un chacun une très forte redondance linguistique. Il me semble que Claude Shannon l’avait estimée à 75 % dans le cadre de la langue anglaise. Pour obtenir ce nombre surprenant, il a lu un texte à ses amis en s’arrêtant aléatoirement dans sa lecture et en leur demandant de deviner la lettre qui allait suivre : ils ont réussi dans 75 % des cas !
J’utilise très peu la compression des données. Il m’arrive de manger mes mots et d’utiliser quelques abréviations sporadiques. Mais ce sont des algorithmes généralement peu efficaces et que je limite au langage familier.
Mes possibilités de chiffrement sont également peu développées. J’ai la possibilité d’utiliser le verlan mais uniquement avec le protocole linguistique “français”.
Concernant le multiplexage, c’est une question délicate. Je maîtrise partiellement le multiplexage temporel en ce sens où je peux commuter dynamiquement pour gérer jusqu’à 3 discussions simultanément (voir l’exemple ci-dessous). En revanche, le multiplexage fréquentiel qui consisterait à parler en même temps à une première personne avec une voix grave et avec une seconde avec une voix aiguë, ce multiplexage là n’est absolument pas supporté. Je ne sais même pas s’il est techniquement possible…
Pierre - Bonjour Jacques
Jacques - Salut Pierre, ça va ?
Henri - Salut Pierre, as-tu vu le dernier Woody Allen ?
Serge - Je dois y aller, à bientôt les amis !
Pierre - Ca va bien Jacques, je te remercie et toi-même ? Non Henri je n’ai pas vu ce film. Au-revoir Serge !
Possibilités d’amélioration
Clairement, prendre en charge le multiplexage fréquentiel serait génial et me permettrait d’obtenir des débits de parole impressionnants car je sous-utilise complètement ma bande-passante.
L’interception du message parlé par un tiers (potentiellement malveillant) reste quand même LA grosse lacune d’un point de vue sécurité. il faudrait que je m’oriente vers un protocole de chiffrage avec clef publique. En ce cas, un codage RSA en temps réel serait super. Je me demande si ça figure au catalogue de la Méthode Assimil…
Liens utiles
https://realpython.com/playing-and-recording-sound-python/
https://simpleaudio.readthedocs.io/en/latest/ https://python-sounddevice.readthedocs.io/en/latest/index.html
https://docs.python.org/fr/3/library/ossaudiodev.html#module-ossaudiodev http://www.opensound.com/pguide/oss.pdf
https://docs.python.org/fr/3/library/wave.html#module-wave